Background prep work
In a mad rush of productivity, I spent my Saturday learning how to use Mechanical Turk to run a syntax experiment. I had already read enough of the background literature, including Colin Phillips' (2010) 'Should we impeach armchair linguists', Wayne Cowart's Experimental Syntax, Chris Potts' post on Language Log 'In defense of Amazon's Mechanical Turk', and a dozen other articles from Sprouse, Gibson, Fedorenko, etc. to feel justified doing experimental work like this -- collecting grammaticality judgments from non-linguist, untrained populations.
Quick, what is Mechanical Turk? Mega-crowdsourcing of surveys. You can post your survey (or experiment stimuli) online to thousands of active users, and pay them. Everything is done online, with a fairly intuitive clicky-through interface. Obviously nice for commerical uses, but some clever people found that it's great for linguistics research!
HIT: Human Intelligence Tasks. A single HIT is like asking "Is this one sentence grammatical, Y/N?". From what I gathered, the going rate for a single HIT is $0.005-$0.02.
Worker: people who take your survey (or answer your question).
Requester: the "researcher". probably you.
I followed Morris Alper's step-by-step MTurk Tutorial to learn how to use the sandbox and practice making experiments. This took a lot of trial and error. I don't think Amazon's setup is that great - the sandbox is just like the real thing. Which unfortunately means there's some delay between publishing your experiment and viewing it, and you have to create separate accounts to administer and test your experiments. But it works. Highly recommended to have a dual monitor (at least) set up.
I was relieved to find that designing the presentation of an experiment is done in HTML! Familiar radio button, form, formatting syntax. Whew. It didn't seem to like Javascript for making a multi-page quiz (the above MTurk Tutorial's Generator produces a multi-page quiz), so I had to present all my stimuli on one single page.
If you want real people responses, you do have to pay them. MTurk requires that you "pre-pay", which means putting some money in your account.
I made good use of Reddit's Mechanical Turk subreddit and searched for tips for Requesters on payment. What I gathered from that forum is a glimpse into the mentality of the population. The typical MTurk Worker is doing things at a very fast pace (sometimes using programs to queue up and find the most efficient surveys). They will pass up surveys that appear to take too much time or pay too little (even though we're talking about cents, here). Workers are operating very quickly so you have to design accordingly. I don't think they'd be sympathetic to long introductory texts, or tasks that require 'training'. You just have to give them the data and ask them to react. The other thing I saw is that tasks paying $1 or $2 are seen as gold. If your task requires a longer survey, say you want 20 judgments from a single individual, worry not - as long as you can compensate accordingly, you will get responses. Lest you think this mentality degrades the quality of the responses, see the Language Log post above for discussion of that. It has been proven in meta-studies again and again that Workers respond just the same as any other population, like a traditional sit-down paper survey that you administer in person.
Making my own survey
Once I went through the survey and I made an ugly survey asking people for 4 grammatical judgments. I posted it, paying a Worker $0.02 if he answers completely. I was ambitious and set my "Desired Number of Responses" (in MTurk terms, "Assignments") at 50. For the first 30 minutes, I got 2 responses. This was exciting, but not nearly as fast as others were saying it should be, and the software projected that it would be completed sometime next morning. Hm.
So I canceled that project, and made a similar one. I cut down on some of the introductory fluff text, upped the pay to $0.05, and made it live.
In the first hour I had 13 responses! I was bouncing off the walls at this point - very exciting. Even more exciting -- I clicked through to see my results, and they were generally supporting my intuition. There is conducting an experiment and seeing it confirm your hunch. I went to dinner, and when I got back, it had finished! I had received 50 responses to my survey, each providing 4 grammatical judgments, in about 3.5 hours. And it cost me $3.50. And this is after maybe 5 hours of reading, designing, testing the experiment in the sandbox, and making it live!
What were my results? Well, I think it's safe to share the boxplot, made in RStudio:
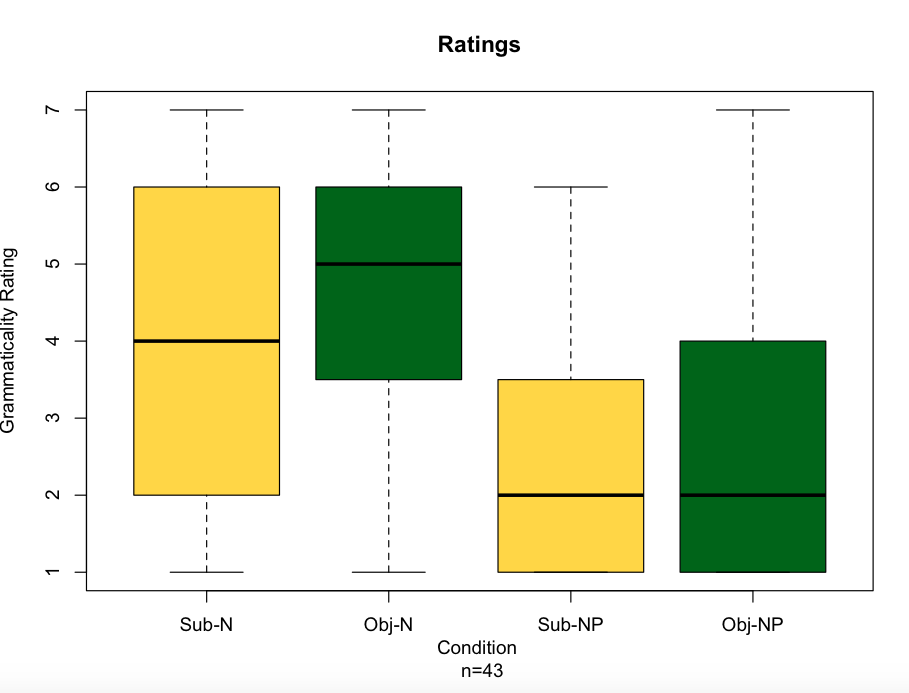
Incredibly, and I believe computing the stats will support this, it seems that there is no subject-object asymmetry here, but there is a category disctinction (N-NP). What is this all about? Well, you'll have to wait for my LCUGA 3 Proceedings article to come out!